Nach dem zuvor beschriebenen Prinzip der Hypothesentests gibt es verschiedene Tests, die auf unterschiedliche Fragestellungen zugeschnitten sind. In diesem Abschnitt werden einige dieser Tests vorgestellt.
Wir werden uns hier auf einige typische Tests konzentrieren. Es gibt noch viele weitere Tests, die auf spezielle Fragestellungen zugeschnitten sind. Die hier vorgestellten Tests gehören jedoch zu den wichtigsten und werden in der Praxis häufig verwendet.
6.1 T-Test
Der t-Test ist eine Klasse von statistischen Tests, die verwendet werden, um Hypothesen über den Mittelwert (oder die Differenz von Mittelwerten) einer oder zweier Stichproben zu prüfen, insbesondere wenn die Standardabweichung der Grundgesamtheit unbekannt ist und aus der Stichprobe geschätzt werden muss.
Beim Einstichproben-t-Test wird der Mittelwert einer Stichprobe mit einem vorgegebenen, hypothetischen Wert (\(\mu_0\)) verglichen. Der Test wird typischerweise verwendet, wenn die Varianz der Grundgesamtheit unbekannt ist und aus der Stichprobe geschätzt wird. Die t-Verteilung berücksichtigt die zusätzliche Unsicherheit, die durch diese Schätzung entsteht.
Wir legen zunächst den Typ-I-Fehler (Signifikanzniveau \(\alpha\)) fest. Damit definieren wir die maximale Wahrscheinlichkeit, die wir zu akzeptieren bereit sind, die Nullhypothese (\(H_0\)) fälschlicherweise abzulehnen, obwohl sie wahr ist (\(P(\text{Ablehnung } H_0 | H_0 \text{ ist wahr}) \leq \alpha\)).
Um zu beurteilen, wie wahrscheinlich die beobachtete Stichprobe unter der Annahme ist, dass die Nullhypothese wahr ist, wird die Teststatistik \(t\) berechnet. Diese misst den Unterschied zwischen dem Stichprobenmittelwert \(\bar{x}\) und dem hypothetischen Wert \(\mu_0\) in Einheiten des Standardfehlers des Mittelwerts. Wörtlich bedeutet die Teststatistik: Um wie viele Standardfehler weicht der Stichprobenmittelwert \(\bar{x}\) vom vorgegebenen Wert \(\mu_0\) ab?
\[
t = \frac{\bar{x} - \mu_0}{s / \sqrt{n}},
\]
wobei \(\bar{x}\) der Stichprobenmittelwert, \(s\) die Stichprobenstandardabweichung (oft wird die korrigierte Stichprobenstandardabweichung verwendet) und \(n\) die Stichprobengröße ist.
Unter der Annahme, dass die Nullhypothese wahr ist und die Daten aus einer normalverteilten Grundgesamtheit stammen, folgt die Teststatistik \(t\) einer t-Verteilung mit \(n-1\) Freiheitsgraden.
Die Entscheidung über die Ablehnung der Nullhypothese hängt von der Alternativhypothese (\(H_1\)) ab:
Bei \(H_1: \mu > \mu_0\) (rechtseitiger Test) lehnen wir \(H_0\) ab, wenn \(t > t_{1-\alpha, n-1}\).
Bei \(H_1: \mu < \mu_0\) (linksseitiger Test) lehnen wir \(H_0\) ab, wenn \(t < t_{\alpha, n-1}\) (was \(t < -t_{1-\alpha, n-1}\) entspricht).
Bei \(H_1: \mu \neq \mu_0\) (zweiseitiger Test) lehnen wir \(H_0\) ab, wenn \(|t| > t_{1-\alpha/2, n-1}\).
Der kritische Wert \(t_{\text{krit}}\) (z.B. \(t_{1-\alpha, n-1}\) oder \(t_{1-\alpha/2, n-1}\)) wird aus der Tabelle der t-Verteilung oder mittels Software bestimmt.
6.1.1.1 Beispiel - Einseitig: Eiweißgehalt von Braugerste
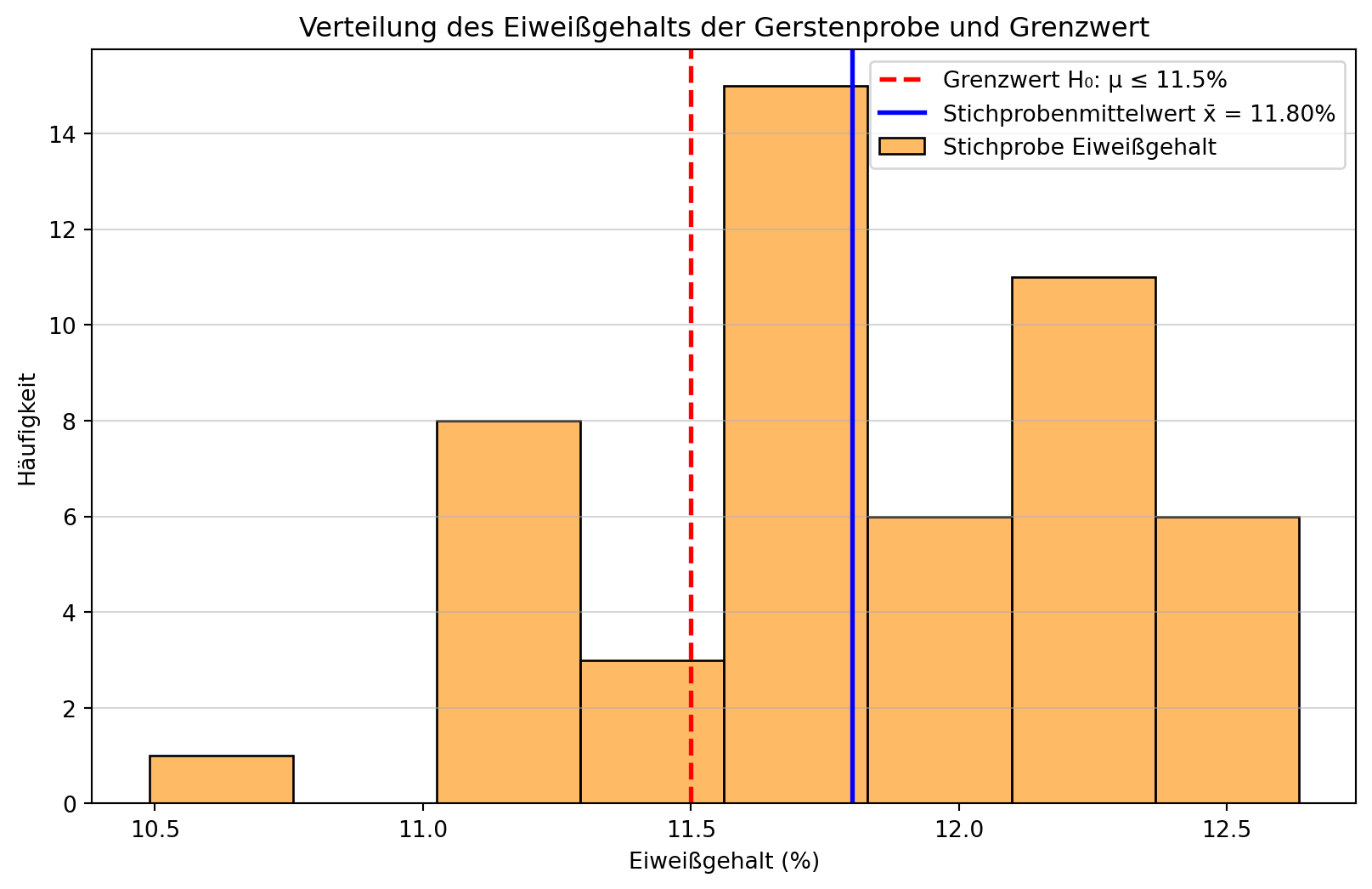
Eine Brauerei bezieht eine neue Charge Gerste. Für den Brauprozess ist es wichtig, dass der mittlere Eiweißgehalt der Gerste einen bestimmten Grenzwert nicht überschreitet, da ein zu hoher Eiweißgehalt zu unerwünscht starkem Schäumen des Bieres führen kann. Der maximal akzeptable mittlere Eiweißgehalt liegt laut Spezifikation bei \(\mu_0 = 11.5\%\).
Die Brauerei möchte prüfen, ob die neue Charge Gerste diese Spezifikation einhält oder ob der mittlere Eiweißgehalt signifikant höher ist. Dazu wird eine Stichprobe von \(n=50\) Körnern aus der Charge entnommen und deren Eiweißgehalt analysiert.
import numpy as npfrom scipy.stats import t as t_dist, normimport matplotlib.pyplot as pltimport seaborn as sns# Annahmen für die Simulation (wären in der Realität unbekannt)# Nehmen wir an, die Charge ist tatsächlich leicht über dem Limittrue_mu_barley =11.8# Tatsächlicher mittlerer Eiweißgehalt der Charge (%)true_sigma_barley =0.5# Tatsächliche Standardabweichung des Eiweißgehalts (%)# Nullhypothese (Grenzwert)mu_0_barley =11.5# Stichprobe ziehenn_barley =50# Setze einen Seed für Reproduzierbarkeitnp.random.seed(2024)X_barley = np.random.normal(true_mu_barley, true_sigma_barley, n_barley)# Schätzer aus der Stichprobe berechnenx_bar_barley = np.mean(X_barley)s_barley = np.std(X_barley, ddof=1) # Korrigierte Stichprobenstandardabweichungprint(f"Stichprobenmittelwert (x̄): {x_bar_barley:.2f}%")print(f"Stichprobenstandardabweichung (s): {s_barley:.2f}%")print(f"Stichprobengröße (n): {n_barley}")# Plot der Stichprobendaten und der Nullhypotheseplt.figure(figsize=(10, 6))sns.histplot(X_barley, bins=8, kde=False, alpha=0.6, label='Stichprobe Eiweißgehalt', color='darkorange', edgecolor='black')plt.axvline(mu_0_barley, color='red', linestyle='--', linewidth=2, label=f'Grenzwert H₀: μ ≤ {mu_0_barley}%')plt.axvline(x_bar_barley, color='blue', linestyle='-', linewidth=2, label=f'Stichprobenmittelwert x̄ = {x_bar_barley:.2f}%')plt.title('Verteilung des Eiweißgehalts der Gerstenprobe und Grenzwert')plt.xlabel('Eiweißgehalt (%)')plt.ylabel('Häufigkeit')plt.legend()plt.grid(axis='y', alpha=0.5)plt.show()
Figure 6.1: Verteilung des Eiweißgehalts in der Stichprobe und der maximal zulässige Mittelwert (Nullhypothese).
Durchführung des Hypothesentests:
Definition der Hypothesen:
\(H_0: \mu \leq 11.5\%\) (Der mittlere Eiweißgehalt der Charge liegt bei oder unter dem Grenzwert). Wir verwenden für die Berechnung den Grenzfall \(H_0: \mu = 11.5\%\).
\(H_1: \mu > 11.5\%\) (Der mittlere Eiweißgehalt der Charge ist höher als der Grenzwert). Wir wählen einen einseitigen Test (rechtsseitig), da uns nur eine Überschreitung des Grenzwerts Sorgen bereitet.
Definition des Signifikanzniveaus:
Die Brauerei legt \(\alpha = 0.05\) fest.
Das Risiko, eine Charge fälschlicherweise als zu eiweißreich abzulehnen, obwohl sie den Grenzwert einhält (\(H_0\) wahr ist), soll maximal 5% betragen.
Berechnung der Teststatistik \(t\):
\(t = \frac{\bar{x} - \mu_0}{s / \sqrt{n}}\)
# Berechnung der Teststatistik für Gerstestandard_error_barley = s_barley / np.sqrt(n_barley)t_statistic_barley = (x_bar_barley - mu_0_barley) / standard_error_barleyprint(f'Standardfehler (s/√n): {standard_error_barley:.4f}')print(f'Teststatistik (t): {t_statistic_barley:.3f}')
Bestimmung des kritischen Wertes \(t_{\text{krit}}\):
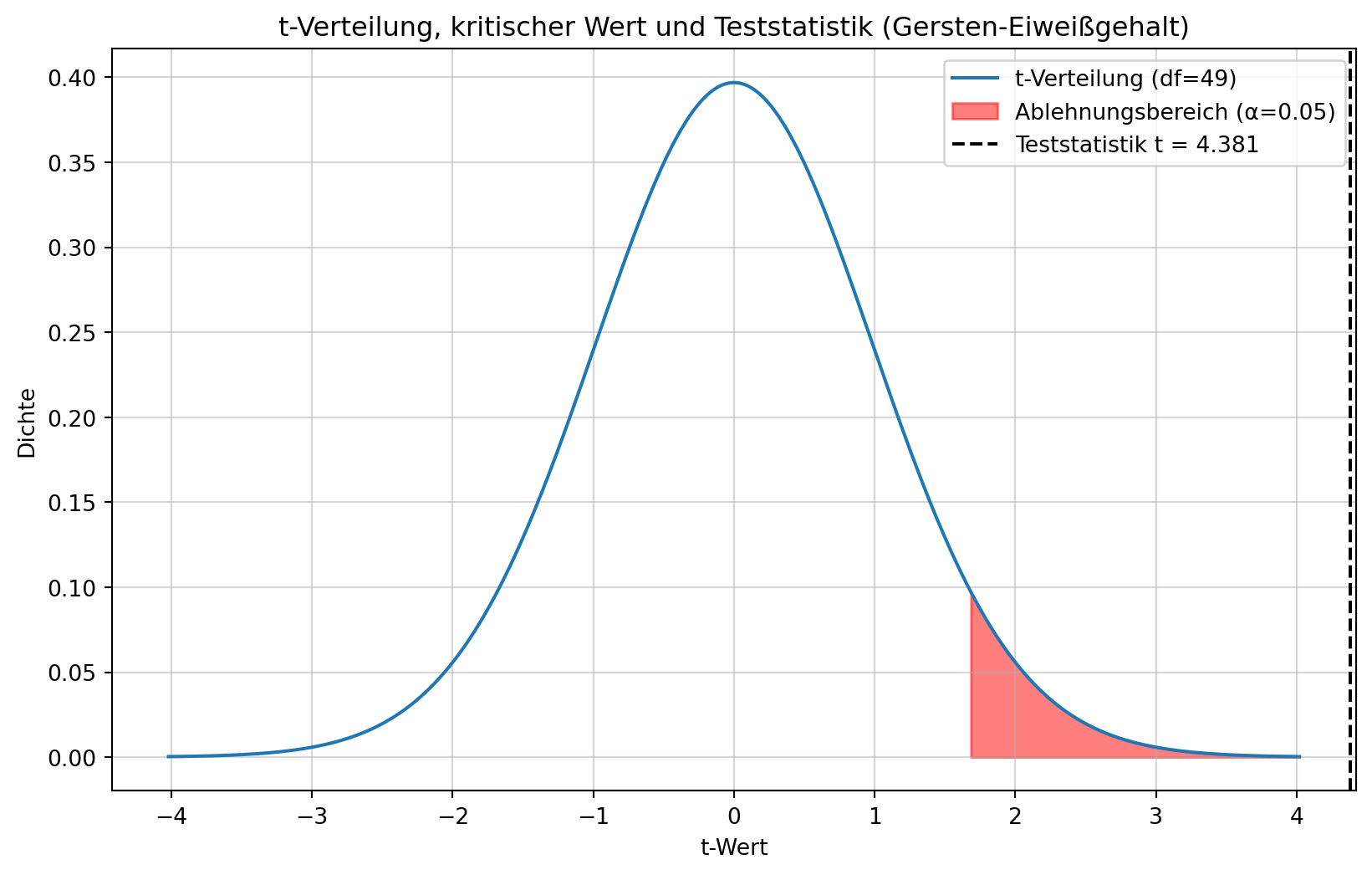
Wir führen einen einseitigen Test (rechtsseitig) mit \(\alpha = 0.05\) und \(n-1 = 50-1 = 49\) Freiheitsgraden durch. Wir suchen den Wert \(t_{1-\alpha, n-1} = t_{0.95, 49}\).
Aus der t-Verteilungstabelle oder mit Software erhalten wir \(t_{\text{krit}} \approx 1.677\).
from scipy.stats import t as t_distalpha_barley =0.05df_barley = n_barley -1# Freiheitsgradet_critical_barley = t_dist.ppf(1- alpha_barley, df_barley)print(f'Freiheitsgrade (df): {df_barley}')print(f'Kritischer Wert (t_krit) für α={alpha_barley} (einseitig): {t_critical_barley:.3f}')
Freiheitsgrade (df): 49
Kritischer Wert (t_krit) für α=0.05 (einseitig): 1.677
Die Visualisierung der t-Verteilung mit dem Ablehnungsbereich hilft, die Entscheidung zu verstehen:
Figure 6.2: t-Verteilung mit 49 Freiheitsgraden und Ablehnungsbereich für den einseitigen Gerstentest (α=0.05).
Note
Zur Erinnerung: Die t-Verteilung beim Testen
Die t-Verteilung beschreibt, wie sich die Teststatistik \(T = \frac{\bar{X} - \mu_0}{S / \sqrt{n}}\) verteilen würde, wenn die Nullhypothese (\(H_0: \mu = \mu_0\)) wahr wäre und die Daten aus einer normalverteilten Grundgesamtheit stammen. Wir vergleichen unseren aus der Stichprobe berechneten Wert \(t\) mit dieser theoretischen Verteilung, um zu sehen, ob er ein plausibler Wert unter \(H_0\) ist oder eher ein extremer, unwahrscheinlicher Wert, der gegen \(H_0\) spricht.
Entscheidung:
Wir vergleichen die Teststatistik \(t\) mit dem kritischen Wert \(t_{\text{krit}}\). Regel: Lehne \(H_0\) ab, wenn \(t > t_{\text{krit}}\).
Da \(t \approx 4.011 > 1.677 \approx t_{\text{krit}}\), lehnen wir die Nullhypothese \(H_0\) ab.
Interpretation: Das Ergebnis ist statistisch signifikant auf dem 5%-Niveau. Es gibt ausreichende Evidenz aus der Stichprobe, um zu schlussfolgern, dass der mittlere Eiweißgehalt dieser Gerstencharge signifikant über dem Grenzwert von 11.5% liegt. Die Brauerei sollte diese Charge möglicherweise nicht verwenden oder entsprechend behandeln, um Probleme mit dem Schaum zu vermeiden.
p-Wert: Berechnung der Wahrscheinlichkeit, unter \(H_0\) eine Teststatistik zu beobachten, die mindestens so extrem ist wie \(t \approx 4.011\).
p_value_barley =1- t_dist.cdf(t_statistic_barley, df_barley)print(f'p-Wert: {p_value_barley:.3e}') # Formatierung in wissenschaftlicher Notation# Vergleich mit alphaif p_value_barley < alpha_barley:print(f"Da p-Wert ({p_value_barley:.3e}) < α ({alpha_barley}), wird H₀ abgelehnt.")else:print(f"Da p-Wert ({p_value_barley:.3e}) >= α ({alpha_barley}), wird H₀ nicht abgelehnt.")
p-Wert: 3.110e-05
Da p-Wert (3.110e-05) < α (0.05), wird H₀ abgelehnt.
Der p-Wert ist sehr klein (\(p \approx 9.98 \times 10^{-5}\)). Das bedeutet, es ist extrem unwahrscheinlich, einen Stichprobenmittelwert wie den beobachteten (oder einen noch höheren) zu erhalten, wenn der wahre mittlere Eiweißgehalt der Charge tatsächlich nur 11.5% (oder weniger) wäre. Da \(p < \alpha\), wird \(H_0\) abgelehnt.
Important
Konsequenz der Testentscheidung
In diesem Beispiel führt die Ablehnung der Nullhypothese zu der Schlussfolgerung, dass der Eiweißgehalt wahrscheinlich zu hoch ist. Dies hat praktische Konsequenzen für die Brauerei (z.B. Ablehnung der Charge, Anpassung des Brauprozesses). Wäre die Nullhypothese nicht abgelehnt worden (\(t \leq t_{krit}\) oder \(p > \alpha\)), hätte die Brauerei keinen statistischen Grund gehabt, die Charge aufgrund des Eiweißgehalts abzulehnen (basierend auf dieser Stichprobe und dem gewählten Signifikanzniveau).
Important
Der p-Wert
Der p-Wert ist die Wahrscheinlichkeit, unter Annahme der Gültigkeit der Nullhypothese (\(H_0\)), ein Ergebnis zu erhalten, das mindestens so extrem ist wie das in der Stichprobe beobachtete Ergebnis (repräsentiert durch die Teststatistik).
Ein kleiner p-Wert (typischerweise \(p \leq \alpha\)) deutet darauf hin, dass das beobachtete Ergebnis unter \(H_0\) sehr unwahrscheinlich ist. Dies liefert Evidenz gegen\(H_0\) und führt zur Ablehnung von \(H_0\).
Ein großer p-Wert (\(p > \alpha\)) bedeutet, dass das beobachtete Ergebnis unter \(H_0\) durchaus plausibel ist. Es gibt keine ausreichende Evidenz, um \(H_0\) abzulehnen.
Der p-Wert ist nicht die Wahrscheinlichkeit, dass \(H_0\) wahr ist.
6.1.1.2 Aufgabe - Zweiseitig: Eiweißgehalt von Braugerste
Eine Brauerei prüft, ob der Eiweißgehalt einer neuen Gerstencharge im optimalen Bereich von 10.5% liegt. Ein zu hoher oder zu niedriger Eiweißgehalt kann die Bierqualität beeinträchtigen. Führen Sie einen zweiseitigen t-Test durch, um zu testen, ob der mittlere Eiweißgehalt der Charge signifikant von 10.5% abweicht. Verwenden Sie eine Stichprobe von \(n=50\) Körnern mit den folgenden Daten:
Stichprobenmittelwert: \(\bar{x} = 10.47\%\)
Stichprobenstandardabweichung: \(s = 0.49\%\)
Signifikanzniveau: \(\alpha = 0.05\)
Hypothesen:
\(H_0: \mu = 10.5\%\) (Der Eiweißgehalt entspricht dem Zielwert).
Zweiseitig: \(H_0\) wird abgelehnt, wenn \(|t| > t_{1-\alpha/2, n-1}\).
Kritischer Wert \(t_{\text{krit}}\) aus einer t-Verteilungstabelle oder Software.
Berechnen Sie die Teststatistik \(t\), den kritischen Wert \(t_{\text{krit}}\) und den p-Wert. Entscheiden Sie, ob \(H_0\) abgelehnt wird, und interpretieren Sie das Ergebnis.
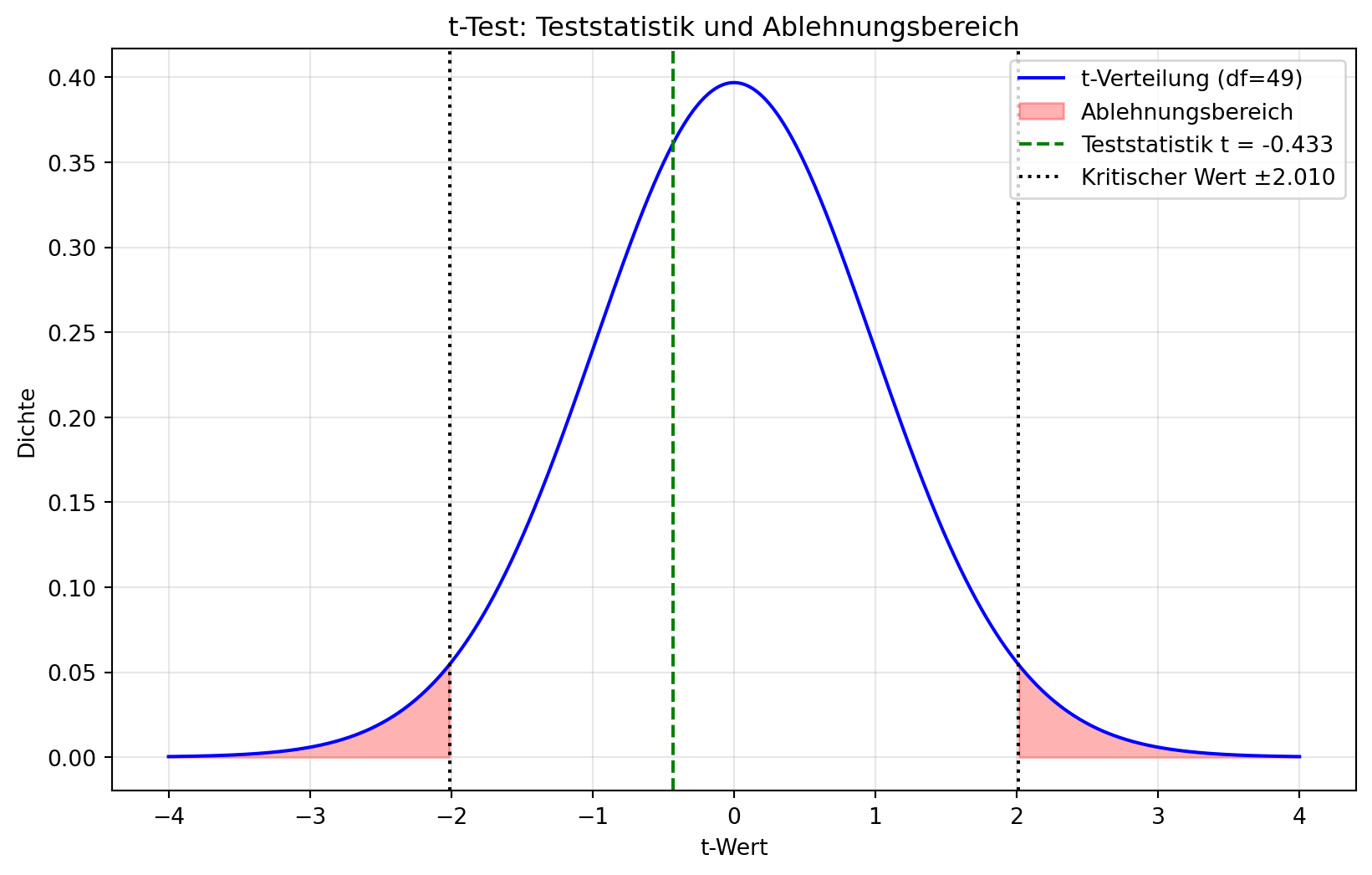
Freiheitsgrade: \(df = n - 1 = 49\). Für einen zweiseitigen Test mit \(\alpha = 0.05\) ist der kritische Wert \(t_{1-\alpha/2, 49} = t_{0.975, 49} \approx 2.010\) (aus t-Tabelle oder Software).
from scipy.stats import t as t_distalpha =0.05df = n -1t_critical = t_dist.ppf(1- alpha/2, df)print(f"Kritischer Wert t_krit: ±{t_critical:.3f}")
Kritischer Wert t_krit: ±2.010
Schritt 4: p-Wert
Der p-Wert für einen zweiseitigen Test ist: \(p = 2 \cdot P(T \geq |t|)\).
Es gibt keinen statistischen Hinweis, dass der Eiweißgehalt der Gerstencharge signifikant von 10.5% abweicht. Die Charge liegt im optimalen Bereich, und die Brauerei kann sie verwenden, ohne Anpassungen vornehmen zu müssen.
Häufig ist man daran interessiert, ob sich die Mittelwerte zweier unabhängiger Stichproben signifikant voneinander unterscheiden. Zum Beispiel könnten wir vergleichen, ob sich die mittlere Zugfestigkeit von Stählen zweier verschiedener Lieferanten unterscheidet. Auch hierfür kann ein t-Test eingesetzt werden (vgl. Abb. Figure 6.4).
Figure 6.4: Grundidee des Zwei-Stichproben-t-Tests: Vergleich der Mittelwerte zweier Verteilungen. Quelle: Inductiveload (n.d.)
Voraussetzungen:
Die beiden Stichproben sind unabhängig voneinander.
Die Daten in beiden Stichproben stammen aus normalverteilten Grundgesamtheiten. (Der Test ist robust gegenüber Verletzungen dieser Annahme bei ausreichender Stichprobengröße, ca. n > 30 pro Gruppe).
Die Varianzen der beiden Grundgesamtheiten sind gleich (\(\sigma_1^2 = \sigma_2^2\)). Diese Annahme kann mit Tests wie dem Levene-Test überprüft werden. Wenn die Varianzen ungleich sind, wird eine Variante des t-Tests namens Welch-Test verwendet, der die Freiheitsgrade anpasst.
Hypothesen (Standardfall: Test auf Gleichheit der Mittelwerte):
\(H_1: \mu_1 \neq \mu_2\) (zweiseitig), oder \(H_1: \mu_1 > \mu_2\) (rechtsseitig), oder \(H_1: \mu_1 < \mu_2\) (linksseitig)
Teststatistik (bei gleichen Varianzen):
Berechne die gepoolte (kombinierte) Varianz\(s_p^2\) als gewichteten Durchschnitt der beiden Stichprobenvarianzen: \[
s_p^2 = \frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}
\] wobei \(n_1, n_2\) die Stichprobengrößen und \(s_1^2, s_2^2\) die (korrigierten) Stichprobenvarianzen sind. \(s_p = \sqrt{s_p^2}\) ist die gepoolte Standardabweichung.
Herleitung der Formel für die gepoolte Varianz
Die gepoolte Varianz ist eine gewichtete Mittelung der beiden Stichprobenvarianzen, wobei die Gewichte den Freiheitsgraden der Stichproben entsprechen.
Berechne die Teststatistik \(t\): \[
t = \frac{(\bar{x}_1 - \bar{x}_2) - (\mu_1 - \mu_2)_0}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}
\] Für den Standardtest auf Gleichheit ist \((\mu_1 - \mu_2)_0 = 0\), also vereinfacht sich die Formel zu: \[
t = \frac{\bar{x}_1 - \bar{x}_2}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}
\]
Freiheitsgrade und Entscheidung:
Die Teststatistik folgt unter \(H_0\) einer t-Verteilung mit \(df = n_1 + n_2 - 2\) Freiheitsgraden.
Bestimme den kritischen Wert \(t_{\text{krit}}\) basierend auf \(\alpha\), den Freiheitsgraden \(df\) und der Alternativhypothese (ein- oder zweiseitig, z.B. \(t_{1-\alpha/2, df}\) für zweiseitig).
Vergleiche \(t\) mit \(t_{\text{krit}}\). Bei einem zweiseitigen Test: Lehne \(H_0\) ab, wenn \(|t| > t_{\text{krit}}\).
Alternativ: Berechne den p-Wert und vergleiche ihn mit \(\alpha\). Lehne \(H_0\) ab, wenn \(p \leq \alpha\).
Note
Test auf eine spezifische Differenz der Erwartungswerte
Statt auf Gleichheit der Mittelwerte (\(\mu_1 - \mu_2 = 0\)) zu testen, könnte man auch prüfen, ob sich die Mittelwerte um einen bestimmten Betrag \(\omega_0\) unterscheiden. Die Nullhypothese wäre dann \(H_0: \mu_1 - \mu_2 = \omega_0\). Die Teststatistik \(t\) wird dann wie folgt berechnet: \[
t = \frac{(\bar{x}_1 - \bar{x}_2) - \omega_0}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}
\] Die Freiheitsgrade der t-Verteilung bleiben \(n_1 + n_2 - 2\) (bei Varianzgleichheit).
In manchen Fällen sind die beiden Stichproben nicht unabhängig, sondern gepaart. Das klassische Beispiel ist eine Messung vor und nach einer Behandlung an denselben Untersuchungseinheiten (z.B. Patienten, Bauteilen). Hier interessiert uns nicht der Unterschied der Mittelwerte unabhängiger Gruppen, sondern der mittlere Unterschied innerhalb der Paare.
Beispiel: Ein Verfahren zum Härten eines metallischen Bauteils soll untersucht werden. Im Experiment wird der Härtegrad von \(n=10\) Bauteilen jeweils vor und nach der Behandlung gemessen.
Tabelle: Härtegrad in HR (Rockwell) vor und nach der Behandlung
Bauteil
1
2
3
4
5
6
7
8
9
10
Vorher
49.1
49.2
49.3
49.4
49.5
49.6
49.7
49.8
49.0
50.0
Nachher
50.2
50.3
50.3
50.2
50.7
50.7
50.8
50.9
51.0
51.1
Differenz (Nachher - Vorher)
1.1
1.1
1.0
0.8
1.2
1.1
1.1
1.1
2.0
1.1
Vorgehen:
Berechne die Differenzen\(d_i = \text{Wert}_{\text{nachher}, i} - \text{Wert}_{\text{vorher}, i}\) für jedes Paar \(i\).
Behandle diese Differenzen \(d_1, d_2, ..., d_n\) als eine einzelne Stichprobe.
Führe einen Einstichproben-t-Test für diese Differenzen durch, um zu prüfen, ob der mittlere Unterschied \(\mu_d\) signifikant von einem bestimmten Wert (meistens 0) abweicht.
Hypothesen (Test auf signifikante Erhöhung):
\(H_0: \mu_d = 0\) (Die Behandlung hat im Mittel keinen Effekt auf die Härte.)
\(H_1: \mu_d > 0\) (Die Behandlung erhöht im Mittel den Härtegrad.)
Berechnungen:
Berechne den Mittelwert der Differenzen \(\bar{d}\) und die Standardabweichung der Differenzen \(s_d\).
Kritischer Wert: Für einen einseitigen Test mit \(\alpha = 0.05\) und \(df = n-1 = 10-1 = 9\) Freiheitsgraden ist \(t_{\text{krit}} = t_{0.95, 9}\).
df_paired = n -1alpha_paired =0.05t_crit_paired = t_dist.ppf(1- alpha_paired, df_paired)print(f'Freiheitsgrade (df): {df_paired}')print(f'Kritischer Wert (t_krit) für α={alpha_paired} (einseitig): {t_crit_paired:.3f}')
Freiheitsgrade (df): 9
Kritischer Wert (t_krit) für α=0.05 (einseitig): 1.833
Der kritische Wert ist \(t_{\text{krit}} \approx 1.833\).
Entscheidung: Da \(t \approx 11.58 > 1.833 \approx t_{\text{krit}}\), lehnen wir \(H_0\) ab.
Interpretation: Es gibt starke statistische Evidenz dafür, dass die Behandlung den Härtegrad der Bauteile signifikant erhöht.
p-Wert:
p_value_paired =1- t_dist.cdf(t_stat_paired, df_paired)print(f'p-Wert (einseitig): {p_value_paired:.3e}')if p_value_paired < alpha_paired:print(f"Da p-Wert ({p_value_paired:.3e}) < α ({alpha_paired}), wird H₀ abgelehnt.")else:print(f"Da p-Wert ({p_value_paired:.3e}) >= α ({alpha_paired}), wird H₀ nicht abgelehnt.")
p-Wert (einseitig): 4.760e-07
Da p-Wert (4.760e-07) < α (0.05), wird H₀ abgelehnt.
Der p-Wert ist extrem klein ($p \approx 1.35 \times 10^{-6}$), was die Ablehnung von $H_0$ bestätigt.
6.2 Chi-Quadrat-Test: Ein nicht-parametrischer Test
Der Chi-Quadrat-Test ist ein nicht-parametrischer Test, der Hypothesen über kategoriale Daten prüft, ohne Annahmen über die Verteilung der Grundgesamtheit zu machen. Er wird häufig als Anpassungstest (Goodness-of-Fit) verwendet, um zu testen, ob beobachtete Häufigkeiten in einer Stichprobe einer erwarteten Verteilung entsprechen.
Die Teststatistik misst die Abweichung zwischen beobachteten (\(O_i\)) und erwarteten (\(E_i\)) Häufigkeiten:
\[
\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}
\]
Unter der Nullhypothese (\(H_0\)) folgt die Statistik einer Chi-Quadrat-Verteilung mit \(k-1\) Freiheitsgraden (\(k\) = Anzahl Kategorien). Ein hoher \(\chi^2\)-Wert spricht gegen \(H_0\).
6.2.1 Beispiel: Bierqualität in einer Brauerei
Eine Brauerei prüft, ob die Qualitätsbewertungen einer neuen Biercharge („Hervorragend“, „Gut“, „Mangelhaft“) der erwarteten Verteilung entsprechen, die auf langjährigen Produktionsdaten basiert (erwartete Anteile: Hervorragend: 60%, Gut: 30%, Mangelhaft: 10%). Stichprobe: \(n=150\) Flaschen.
Beobachtete Häufigkeiten:
Hervorragend: 95
Gut: 45
Mangelhaft: 10
Erwartete Häufigkeiten:
Hervorragend: \(150 \times 0.60 = 90\)
Gut: \(150 \times 0.30 = 45\)
Mangelhaft: \(150 \times 0.10 = 15\)
Hypothesen:
\(H_0\): Die Qualitätsverteilung der neuen Biercharge entspricht der erwarteten Verteilung.
\(H_1\): Die Qualitätsverteilung weicht von der erwarteten Verteilung ab.
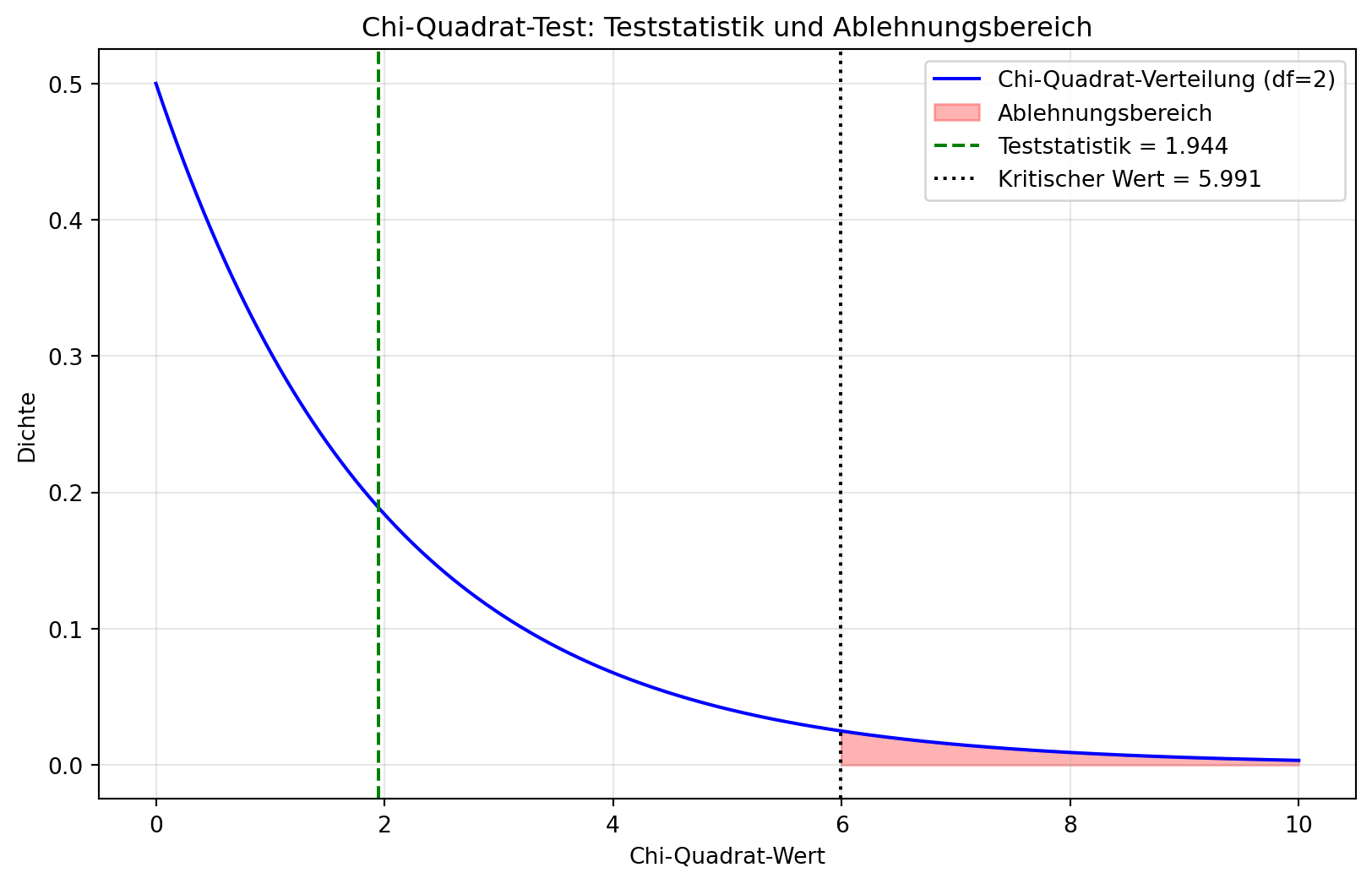
Da \(\chi^2 \approx 1.667 < 5.991\) und \(p \approx 0.435 > 0.05\), wird \(H_0\) nicht abgelehnt.
Interpretation:
Es gibt keinen statistischen Hinweis, dass die Qualitätsverteilung der neuen Biercharge signifikant von der erwarteten Verteilung abweicht. Die Brauerei kann die Charge als qualitativ gleichwertig betrachten.
6.2.3 Warum ist der Chi-Quadrat-Test nicht-parametrisch?
Der Chi-Quadrat-Test macht keine Annahmen über die Verteilung der zugrunde liegenden Daten (z. B. Normalverteilung), sondern arbeitet direkt mit Häufigkeiten. Dies macht ihn besonders geeignet für kategoriale Daten, bei denen parametrische Annahmen wie Normalität oder gleiche Varianzen nicht zutreffen.
6.3 Übersicht über Statistische Tests
Statistische Tests werden verwendet, um Hypothesen über eine Grundgesamtheit anhand einer Stichprobe zu prüfen. Sie bestehen aus einer Nullhypothese (\(H_0\)), die den Status quo repräsentiert, und einer Alternativhypothese (\(H_1\)), die angenommen wird, wenn \(H_0\) abgelehnt wird. Tests helfen, zu unterscheiden, ob die Ergebnisse einer Stichprobe auf die Grundgesamtheit übertragbar sind oder zufällig entstanden.
Nicht-parametrische Tests (z. B. Chi-Quadrat-Test, Mann-Whitney-U-Test) sind flexibler und benötigen keine Verteilungsannahmen, eignen sich aber oft für ordinal oder kategoriale Daten.
Weitere Details zu Testarten findest du in dieser Übersicht.

{kind=link}