1 Data Science, Statisik, und Machine Learning
Data Science, Statisik, Machine Learning und Küstliche Intelligenz sind Begriffe, die in den letzten Jahren immer häufiger in den Medien und in der Wissenschaft auftauchen.
Es gibt unterschiedlichte Definitionen für diese Begriffe, die sich je nach Kontext und Anwendungsbereich unterscheiden. Damit wir uns verstehen, versuchen wir es so:
- Data Science ist ein interdisziplinäres Feld, das sich mit der Extraktion von Wissen aus Daten beschäftigt. Es kombiniert Konzepte aus Statistik, Informatik und Domänenwissen, um Muster und Erkenntnisse aus Daten zu gewinnen. Auch wenn sich hier das Wort Science im Namen befindet, geht es uns hier vorallem, um die Praktische Kompetenz Daten mit den richtigen Werkzeugen und Methoden zu analysieren.
- Statisik ist ein Teilgebiet der Mathematik, das sich mit der Sammlung, Analyse, Interpretation und Präsentation von Daten beschäftigt. In erster Linie schult statischtisches Denken den Geist, auch weit über das Feld der Datenanalyse hinaus.
- Machine Learning beschäftigt sich damit Modelle aus Daten zu generieren, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen zu treffen.
- Künstliche Intelligenz beschreibt alles was zum aktuellen Zeitpunkt noch nicht verstanden ist. Es ist ein Sammelbegriff für alle Technologien, die es Computern ermöglichen, menschenähnliche Aufgaben zu erfüllen.
Um uns in unseren folgenden Abenteuern zurrechtzufinden, beschäftigen wir uns zunächst hier in Chapter 1 mit dem gundlegenden Herangehen an Data Science-Probleme. In Chapter 2 mit den Daten, die wir analysieren wollen.
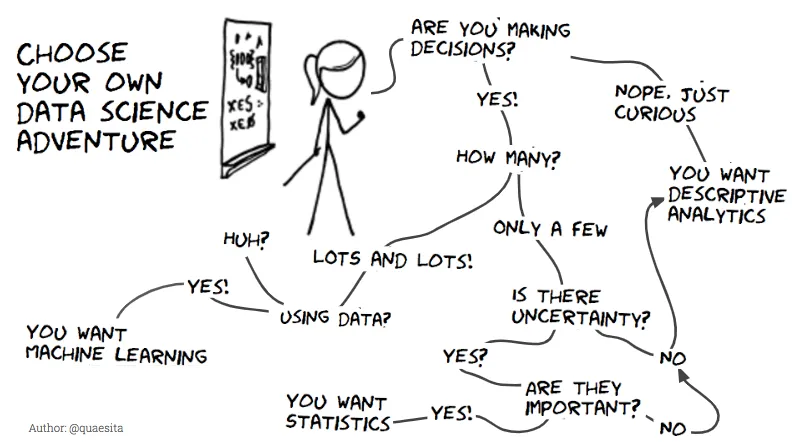
Figure 1.1 zeigt einige der vielen Entscheidungen, die wir treffen müssen, wenn wir uns in unserem eigenen Projekt bewegen.
1.1 Data Sciene: Projektvorgehen
Selbst, wenn uns das Ziel klar ist, können wir uns immernoch verlaufen. Um dies zu verhindern, gibt es verschiedene Vorgehensweisen, die uns helfen auf dem Pfad zu bleiben und uns helfen ein tiefgehendes Verständnis für einen Datensatz zu entwickeln. Hierbei unterstützen Standardvorgehensweisen wie CRISP-DM (Cross-Industry Standard Process for Data Mining Figure 1.2) Shearer (2000). Es gibts aber auch neuere und spezifische Prozesse, die in bestimmten Bereichen, wie z.B. im Feld der Zeitreihenprognosen Hyndman (2018), angewendet werden. Für den Anfang begnügen wir uns jedoch mit dem etabliertesten und verbreitesten Prozess.
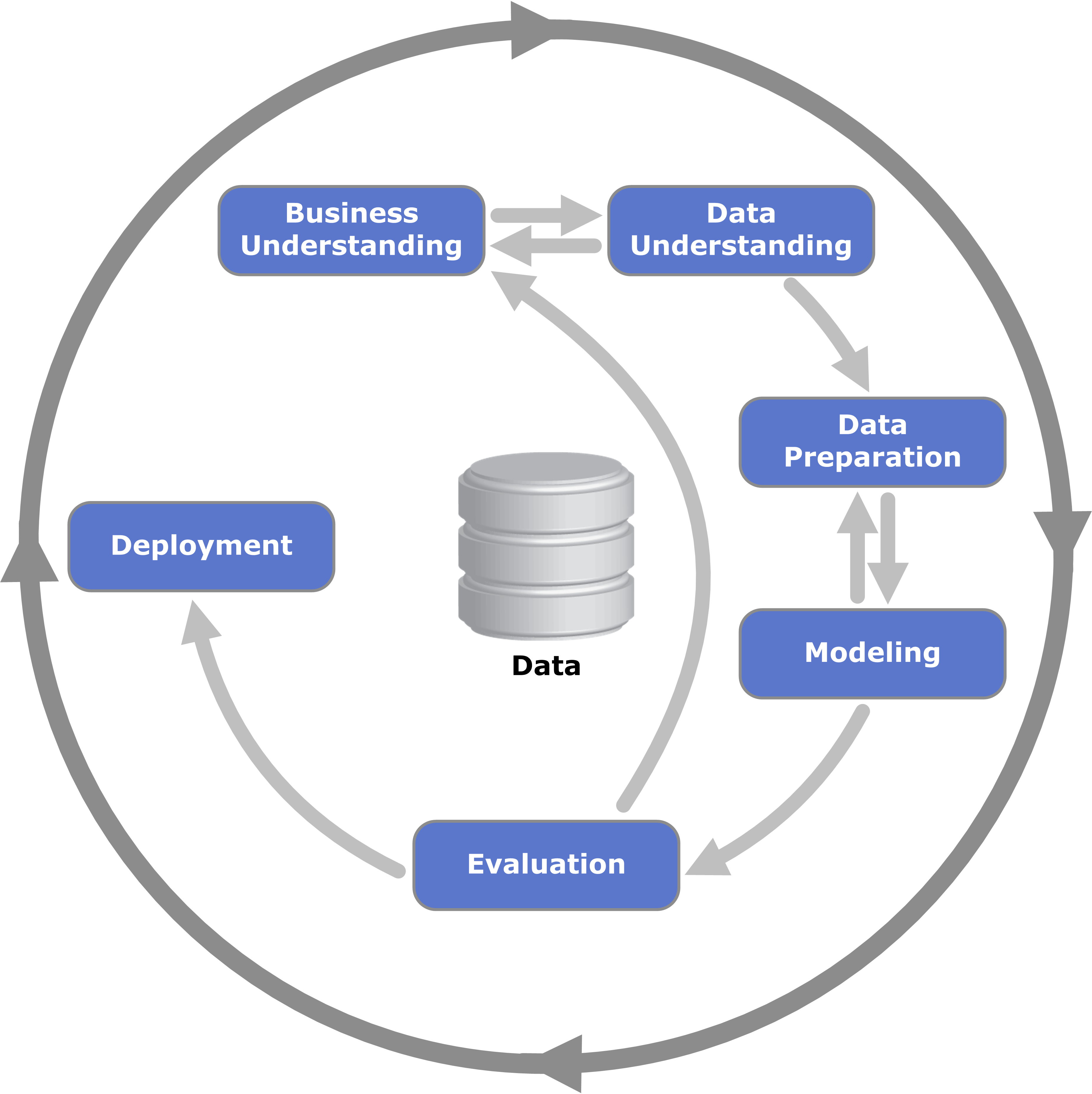
1.1.1 CRISP-DM: Ein systematischer Ansatz für datenbezogene Projekte
Der CRISP-DM-Prozess stellt ein generisches Rahmenwerk dar, das es ermöglicht, datengetriebene Projekte von der Problemdefinition bis hin zur operativen Anwendung zu strukturieren. Der Prozess ist in sechs zentrale Phasen unterteilt:
Business Understanding
Ziel ist es, die geschäftlichen Anforderungen und Problemstellungen klar zu definieren. Diese Phase umfasst Fragestellungen wie: Was möchten wir mit den Daten lösen? oder Welche Ergebnisse und Metriken sind entscheidend für den Erfolg?Data Understanding
Hier wird das vorliegende Datenmaterial genauer untersucht, einschließlich seiner Struktur, Störfaktoren und potenzieller Verzerrungen. Eine erste Erkundung der Daten kann entscheidend sein, um Hypothesen zu entwickeln.Datenaufbereitung
In dieser Phase werden die Rohdaten bereinigt und in ein Format gebracht, das für die Analyse geeignet ist (vgl. Chapter 2). Aktivitäten umfassen das Entfernen fehlender Werte, Transformation von Variablen und die Auswahl relevanter Features.Modellierung
Aufbau eines Modells zur Beantwortung der Kernfrage. Hierbei kann z. B. ein Regressionsmodell für Prognosen oder ein Klassifikationsmodell bei Entscheidungsproblematiken im Vordergrund stehen.Evaluierung
Überprüfung, ob das Modell tatsächlich valide und praktisch anwendbar ist. Kernfragen sind: Passt das Modell zu unseren Zielen? und Sind die Ergebnisse sinnvoll und umsetzbar?Deployment (Inbetriebnahme)
Das Modell wird implementiert, um tatsächliche Entscheidungen oder Vorhersagen zu unterstützen. Dies könnte z. B. bedeuten, ein automatisiertes System zu schaffen, das regelmäßig aktualisierte Prognosen liefert.
Tipp: Obwohl der Prozess linear erscheint, sind Rücksprünge oft unvermeidlich, z. B. wenn das Modell nicht ausreichend Performanz liefert oder die Anforderungen sich ändern. Auch werden wir mehr über der Daten und die Prozesse (Schritte 2 und 3) lernen, je mehr wir uns mit den Daten beschäftigen.
1.1.2 Data Science als People Business?
Es ist wichtig zu erkennen, dass Daten allein nur einen Ausschnitt der Realität darstellen und ohne Kontext wenig nützen. Ein Kernelement ist daher, sich ausreichendes Domänenwissen anzueignen, um die Semantik der zugrunde liegenden Daten zu interpretieren. Häufig kann es dabei hilfreich sein, Daten aus angrenzenden Kontexten hinzuzuziehen und den Dialog mit Expert:innen oder Personen mit Erfahrungswissen zu suchen.
Als Standardvorgehen für viele datenbasierte Projekte empfiehlt Hyndman (2018) in seinem einflussreichen Werk zur Zeitreihenanalyse, diese Prinzipien auch auf Prognosen anzuwenden, ähnliches gibt aber für alle Probblem.
Wenn wir historische Verkaufsdaten eines Geschäfts analysieren, um zukünftige Trends zu prognostizieren, sollten wir sowohl mit der späteren Nutzer:in des Forecasts (z.B. Produktionsplaner:in für das Business Understanding), als auch mit den Erzeugen der Daten (z.B. Sales-Abteilung für das Data Understanding) sprechen.
- Dieses bestimmt, wie unsere Modellierung aussehen soll.
- Wie weit in die Zukunft müssen wir vorhersagen (Prognosehorizont)?
- Welche Auflösung benötigt unsere Prognose (z.B. tagescharf oder wöchtentlich)?
- In welche Systeme (z.B. Dashboards) muss die Prognose später deployed werden?
- Wie soll das Modell evaluiert werden (z.B. ist es wichtiger an keinem Tag große Ausreißer zu haben oder die kumulativen Absatzzahlen über das Jahr hinweg genau zu treffen?)
- Durch Gespräche mit weiteren Stakeholdern ergibt sich zudem Business & Data Understanding
- Gibt es saisonale Effekte (z.B. Insekten-Schutz-Produkte)
- Gibt es systematische Fehler in der Datenaufzeichntung (End-of-Year-Effecs)
- Gab es Systemumstellungen in der Datenerfassung oder andere Externe Brüche (z.B. Markteintritte)
Die Herausforderung ist hierbei jedoch, dass Prognosen fehleranfällig sind. Ein plötzlicher Markteinbruch oder ein externes Ereignis, wie ein sozioökonomischer Schock, könnte die Vorhersagen unbrauchbar machen. Evtl. gehört zum Business Understanding auch die Grenzen einer datanbasierenden Lösung zu verstehen.
1.1.3 Ein Beispiel-Datenset: loan50
Im Folgenden nutzen wir das loan50-Datenset, das aus dem Lehrbuch von Diez, Barr, and Cetinkaya-Rundel (2019) stammt und zur Erkundung solcher Fragestellungen dient.
Das loan50-Datenset enthält Informationen zu 50 vergebenen Krediten, die über die Lending Club Plattform vermittelt wurden. Diese Plattform ermöglicht es Einzelpersonen, untereinander Kredite zu vergeben. Wie in vielen Finanzanwendungen sind jedoch nicht alle Kreditnehmer:innen gleich:
- Kandidat:innen mit hoher Rückzahlungssicherheit werden bevorzugt behandelt und erhalten in der Regel Kredite mit niedrigeren Zinssätzen.
- Risikoreichere Antragsteller:innen könnten hingegen keine Angebote erhalten oder hohe Zinssätze ablehnen.
Achtung: Dieses Datenset enthält nur tatsächlich vergebene Kredite und repräsentiert daher nur eine Teilmenge aller möglichen Kreditanfragen. Diese Einschränkung kann dazu führen, dass wir relevante Informationen über nicht vergebene Kreditanträge nicht betrachten. Solche Probeme bezeichnet man gemeinhin als Bias (Verzerrung).
Einige der verfügbaren Variablen:
Die unten aufgelisteten Variablen beschreiben die Eigenschaften des umfassenderen loans_full_schema-Datensatzes, wovon eine Teilmenge im loan50-Datenset enthalten ist.
| Variable | Beschreibung |
|---|---|
emp_title |
Berufsbezeichnung |
emp_length |
Anzahl der Jahre im Beruf (aufgerundet, Werte über 10 Jahre werden als 10 dargestellt) |
state |
US-Bundesstaat (zweistellige Abkürzung) |
home_ownership |
Wohnsituation der Bewerber:innen (z. B. Eigentum, gemietet) |
annual_income |
Jährliches Einkommen |
verified_income |
Art der Verifikation des Einkommens |
debt_to_income |
Schulden-Einkommens-Verhältnis |
grade |
Bewertung des Kredits, wobei A die höchste Stufe ist |
| … | Weitere Variablen finden Sie in der vollständigen Beschreibung: loan50 - OpenIntro Dataset |
- Welche Fragestellungen könnten mit diesem Datensatz beantwortet werden?
- Beispielsweise: Gibt es einen Zusammenhang zwischen dem Schulden-Einkommens-Verhältnis und der Kreditbewilligung?
- Was müsste noch bekannt sein, um die Daten besser zu verstehen?
- Welche spezifischen Regeln wurden aufgestellt, um Kredite zu vergeben oder abzulehnen?
- Wo bestehen potenzielle Verzerrungen (z. B. durch die fehlenden Daten zu abgelehnten Anträgen)?