Klassifikation ist eine Methode des überwachten Lernens, bei der die abhängige Variable \(Y\) kategorisch ist, d.h., sie nimmt diskrete Werte an (z.B. “ja/nein” oder “USA/nicht USA”). Ziel der Klassifikation ist es, die Wahrscheinlichkeit zu schätzen, dass eine Beobachtung zu einer bestimmten Klasse gehört. Dieses Kapitel konzentriert sich auf binäre Klassifikation und verwendet den Auto-Datensatz.
Wir klassifizieren, ob ein Auto aus den USA stammt (origin == "USA", kodiert als 1) oder nicht (origin != "USA", kodiert als 0), z.B. basierend auf horsepower und weight. In diesem Fall haben wir eine einzelne Dummy-Variable als Zielvariable, die angibt, ob das Auto aus den USA stammt oder nicht.
Warum keine lineare Regression für Klassifikation?
Die lineare Regression ist für kontinuierliche Zielvariablen geeignet, aber unpassend für binäre Klassifikation (z.B. \(Y \in \{0, 1\}\)), da sie:
Ungeeignete Vorhersagen liefert: Die vorhergesagten Werte \(\hat{y} = \beta_0 + \beta_1 X\) können beliebige reelle Zahlen sein, nicht nur Werte zwischen 0 und 1, wie es für Wahrscheinlichkeiten \(p(Y=1 | X)\) erforderlich ist. Dies führt zu negativen oder >1 Wahrscheinlichkeiten.
Falsche Annahmen trifft: Lineare Regression geht von normalverteilten Fehlern aus, während binäre Daten binomialverteilt sind.
Inadäquate Modellierung: Sie kann die S-förmige Beziehung zwischen Prädiktoren und Wahrscheinlichkeiten nicht erfassen, wie es die logistische Regression mit der Sigmoid-Funktion \(p(Y=1 | X) = \frac{e^{\beta_0 + \beta_1 X}}{1 + e^{\beta_0 + \beta_1 X}}\) tut.
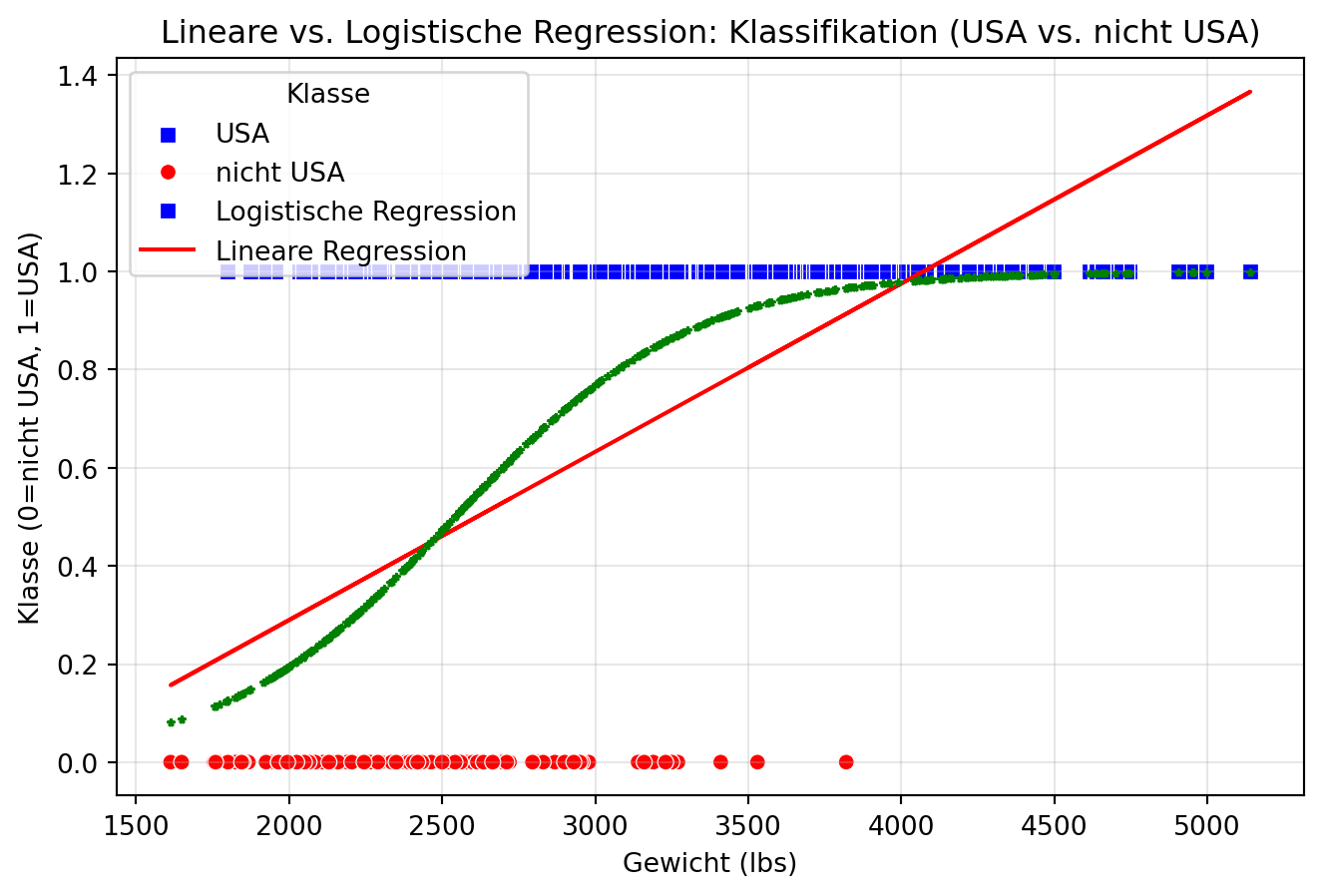
Beispiel mit dem Auto-Datensatz: Wir versuchen, zu klassifizieren, ob ein Auto aus den USA stammt (origin == "USA", kodiert als 0/1), basierend auf horsepower. Eine lineare Regression wird mit einer logistischen Regression verglichen, und die Ergebnisse werden visualisiert.
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LinearRegressionimport statsmodels.api as sm# Lade den Datensatzdf = pd.read_csv(r"../_assets/regression/Auto_Data_Set_963_49.csv")df["origin"] = df["origin"].map({1: "USA", 2: "Europe", 3: "Japan"})df["is_usa"] = (df["origin"] =="USA").astype(int)# Prädiktor und ZielvariableX = df[["weight"]]y = df["is_usa"]# Modell 1: Lineare Regressionlin_reg = LinearRegression()lin_reg.fit(X, y)y_pred_lin = lin_reg.predict(X)# Modell 2: Logistische RegressionX_const = sm.add_constant(X)logit_model = sm.Logit(y, X_const).fit(disp=0)y_pred_logit = logit_model.predict(X_const)# Plotplt.figure(figsize=(8, 5))# Scatterplot mit hue für Klassesns.scatterplot(x=df["weight"], y=df["is_usa"], hue=df["is_usa"], style=df["is_usa"], palette={0: "red", 1: "blue"}, markers={0: "o", 1: "s"}, legend="full")# Lineare Regressionplt.plot(df["weight"], y_pred_lin, color="red", label="Lineare Regression")# Logistische Regressionplt.plot(df["weight"], y_pred_logit, color="green", label="Logistische Regression", linestyle="", marker="*", markersize=3)plt.xlabel("Gewicht (lbs)")plt.ylabel("Klasse (0=nicht USA, 1=USA)")plt.title("Lineare vs. Logistische Regression: Klassifikation (USA vs. nicht USA)")plt.legend(title="Klasse", loc="upper left", labels=["USA", "nicht USA","Logistische Regression", "Lineare Regression"])plt.grid(True, alpha=0.3)plt.show()
Ergebnis und Interpretation: Der Plot zeigt, dass die lineare Regression ungeeignete Werte liefert: Für kleine horsepower-Werte werden negative Wahrscheinlichkeiten vorhergesagt, und für große Werte können Wahrscheinlichkeiten >1 auftreten. Die logistische Regression hingegen liefert eine S-förmige Kurve, die Wahrscheinlichkeiten korrekt zwischen 0 und 1 hält und die Daten besser modelliert.
10.1 Logistische Regression
Die logistische Regression ist ein Standardmodell für binäre Klassifikation. Sie schätzt die Wahrscheinlichkeit \(p(Y=1 | X)\), dass \(Y=1\) ist, gegeben die Prädiktoren \(X\). Die logistische Funktion (Sigmoid-Funktion) stellt sicher, dass die vorhergesagte Wahrscheinlichkeit zwischen 0 und 1 liegt:
Diese Darstellung ist nicht-linear, was bedeutet, dass die Beziehung zwischen den Prädiktoren und der Wahrscheinlichkeit nicht linear ist. Wir können Sie also nicht mit dem OLS-Ansatz (Ordinary Least Squares) die optimalen Koeffizienten \(\beta_0, \beta_1, \ldots, \beta_p\) finden. Allerdings können wir das Problem auch so umformulieren, dass wir eine Linearität herstellen:
Hierbei stellen \(\frac{p}{1 - p}\) die Odds (Chancen) dar, dass \(Y=1\) ist. Die Odds sind das Verhältnis der Wahrscheinlichkeit, dass \(Y=1\) ist, zu der Wahrscheinlichkeit, dass \(Y=0\) ist. Anwendung finden Sie heute z.B. in Sportswetten, wo die Quoten die Chancen für den Gewinn eines Teams darstellen.
10.1.1 Beispiel mit dem Auto-Datensatz
In der Anwendung verändert sich für uns wenig. Unsere Zielvariable y ist binär (Zugehörigkeit zur Klassen), und wir verwenden die logistische Regression, um die Wahrscheinlichkeit zu schätzen, dass ein Auto aus den USA stammt. Wir verwenden horsepower und weight als Prädiktoren.
import pandas as pdimport statsmodels.api as sm# Lade den Datensatzdf = pd.read_csv(r"../_assets/regression/Auto_Data_Set_963_49.csv")df["origin"] = df["origin"].map({1: "USA", 2: "Europe", 3: "Japan"})df["is_usa"] = (df["origin"] =="USA").astype(int)# Prädiktoren und ZielvariableX = df[["horsepower", "weight"]]X = sm.add_constant(X)y = df["is_usa"]# Fitte logistische Regressionlogit_model = sm.Logit(y, X).fit()print(logit_model.summary())
Ergebnis: Die Koeffizienten zeigen den Einfluss der Prädiktoren. Ein positiver Koeffizient für weight bedeutet, dass schwerere Autos eher aus den USA stammen, während ein negativer Koeffizient für horsepower darauf hinweist, dass Autos mit höherer Leistung weniger wahrscheinlich aus den USA kommen. Allerdings sin die genauen Werte der Koeffizienten nicht direkt interpretierbar, da sie die Veränderung der Log-Odds darstellen.
10.2 Evaluation der Ergebnisse
Für jede Klassifikation mit dem Modell schätzen wir eine Wahrscheinlichkeit \(p(Y=1 | X)\), die angibt, wie wahrscheinlich es ist, dass ein Auto aus den USA stammt. Hierbei können wir richtig liegen oder auch nicht.
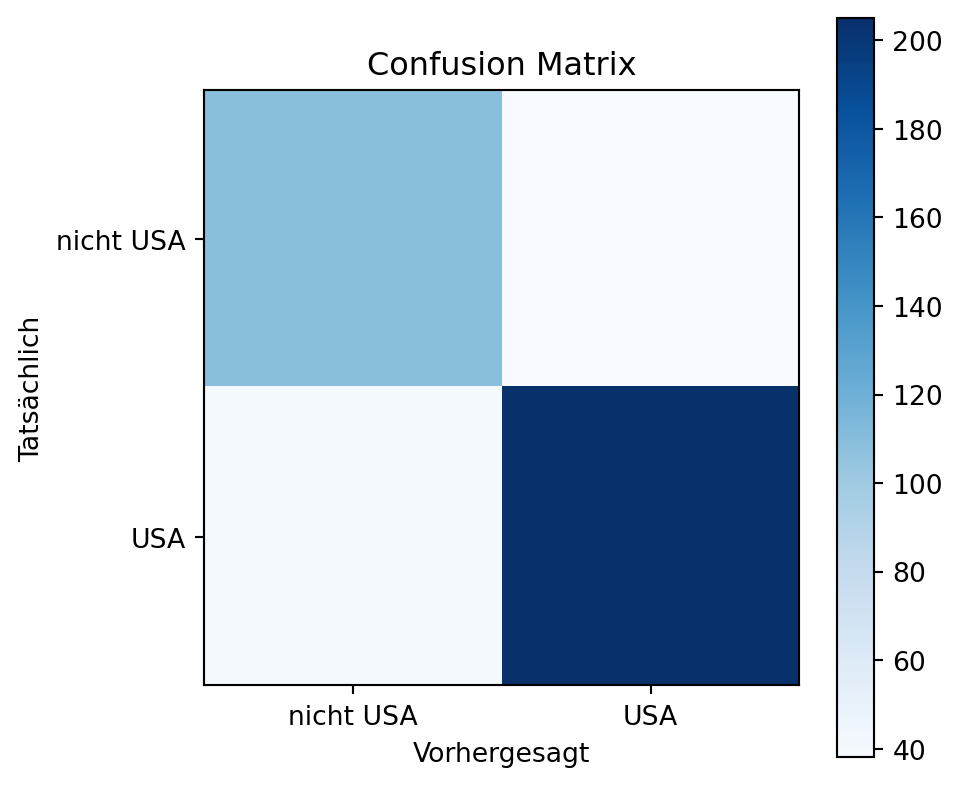
10.2.1 Confusion Matrix
Die Confusion Matrix bewertet die Leistung eines Klassifikationsmodells, indem sie korrekte und falsche Vorhersagen in einer Tabelle darstellt:
True Positives (TP): Korrekte positive Vorhersagen (USA, wenn wirklich aus USA).
True Negatives (TN): Korrekte negative Vorhersagen (nicht USA, wenn nicht aus USA).
False Positives (FP): Falsche positive Vorhersagen (Typ-I-Fehler) (USA, wenn nicht aus USA).
False Negatives (FN): Falsche negative Vorhersagen (Typ-II-Fehler) (nicht USA, wenn wirklich aus USA).
Beim T-Test sind diese Fehler vergleichbar, wenn wir die Nullhypothese ablehnen, obwohl sie wahr ist (FP) oder die Nullhypothese nicht ablehnen, obwohl sie falsch ist (FN).
10.2.1.1 Beispiel mit dem Auto-Datensatz
Wir klassifizieren Autos als “USA” oder “nicht USA” mit einem Schwellenwert von 0.5:
Ein Corona-Test-Beispiel verdeutlicht die Fehlerarten:
Hat Corona (\(y\))
Testwahrscheinlichkeit (\(\hat{p}(y)\))
Klassifikation (Schwelle 0.5)
Fehlerart
0
0.4
0
TN
1
0.9
1
TP
0
0.7
1
FP
1
0.4
0
FN
Die Confusion Matrix dazu:
Vorhergesagt 0
Vorhergesagt 1
Tatsächlich 0
TN = 1
FP = 1
Tatsächlich 1
FN = 1
TP = 1
Hier sehen wir, dass ein FN (falsch negativ) gefährlich sein könnte, da eine infizierte Person nicht erkannt wird. Eine Möglichkeit, dies zu verbessern, wäre die Anpassung des Schwellenwerts (Thresholds), um die Sensitivität zu erhöhen, auch wenn dies die Spezifität verringert. Wenn wir z.B. sicherstellen wollen, dass alle infizierten Personen erkannt werden, könnten wir den Schwellenwert auf 0.3 senken, was zu mehr TP führen würde, aber auch die FP erhöhen könnte.
Hat Corona (\(y\))
Testwahrscheinlichkeit (\(\hat{p}(y)\))
Klassifikation (Schwelle 0.3)
Fehlerart
0
0.4
1
FP
1
0.9
1
TP
0
0.7
1
FP
1
0.4
1
TP
Die Confusion Matrix dazu:
Vorhergesagt 0
Vorhergesagt 1
Tatsächlich 0
TN = 0
FP = 2
Tatsächlich 1
FN = 0
TP = 2
Die Anpassung des Schwellenwerts ist eine gängige Praxis, um die Balance zwischen Sensitivität und Spezifität zu steuern, abhängig von den Anforderungen der spezifischen Anwendung. Dabei wird das eigentliche Modell nicht verändert, sondern nur die Entscheidung, ab welcher Wahrscheinlichkeit eine Klasse zugeordnet wird.
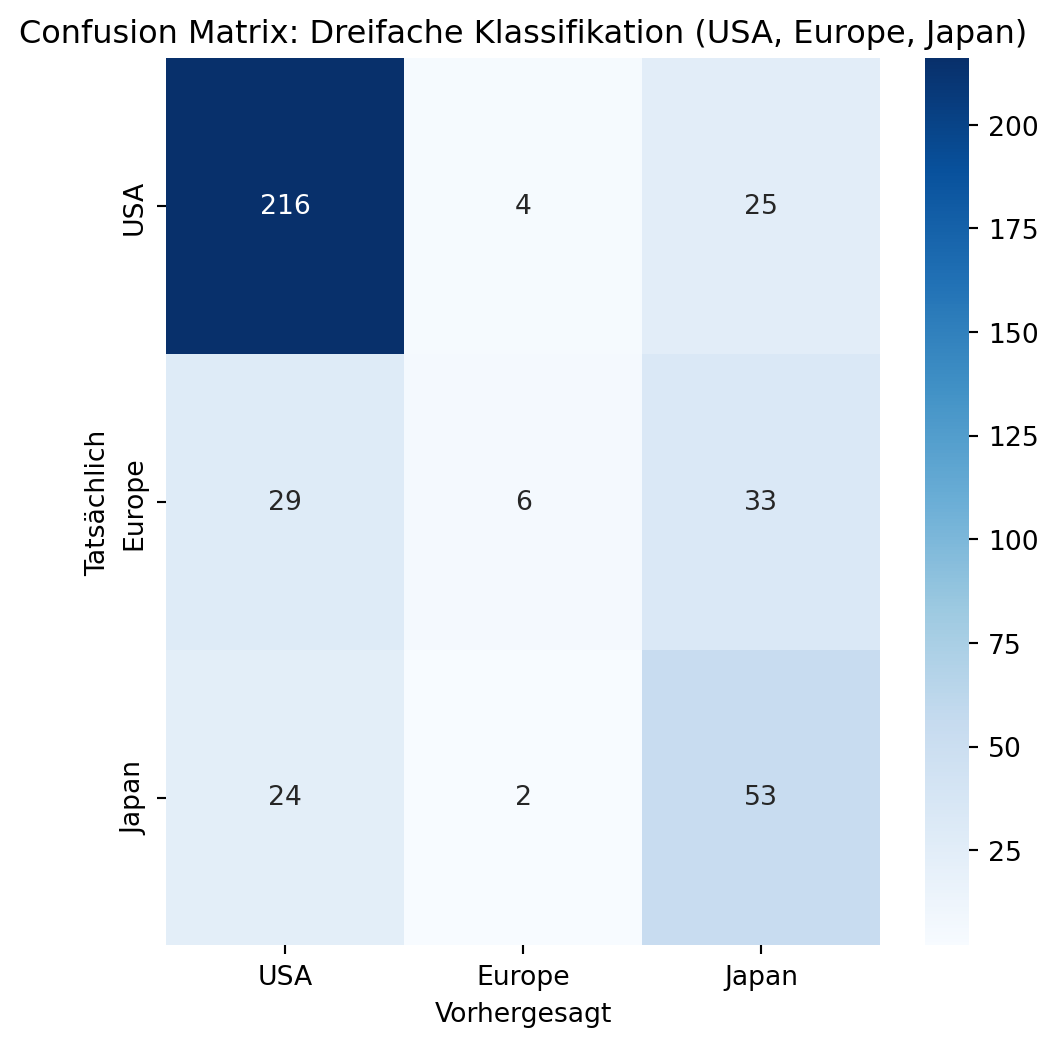
Multi-Class Klassifikation: Confusion Matrix für dreifache Klassifikation
Es gibtverschiedene Möglichkeiten einen Klassifikator für mehr als zwei Klassen zu erstellen. Bei der logistischen Regression können einfach drei Klassen (z.B. “USA”, “Europe”, “Japan”) als binäre Klassifikationen behandelt werden, indem für jede Klasse ein separates Modell trainiert wird. Die Confusion Matrix für binäre Klassifikation lässt sich auf Multi-Class Klassifikation erweitern, indem sie für jede Klasse die korrekten und falschen Vorhersagen darstellt. Bei einer dreifachen Klassifikation mit Klassen \(C_1, C_2, C_3\) (z.B. “USA”, “Europe”, “Japan”) ist die Matrix eine \(3 \times 3\)-Tabelle, wobei:
Diagonalelemente (\(cm_{ii}\)): Anzahl der korrekten Vorhersagen für Klasse \(i\) (True Positives für diese Klasse).
Nicht-Diagonalelemente (\(cm_{ij}\), \(i \neq j\)): Anzahl der falschen Vorhersagen, bei denen Klasse \(i\) tatsächlich ist, aber Klasse \(j\) vorhergesagt wurde.
Formel für Genauigkeit (Accuracy): \(\text{Accuracy} = \frac{\sum_{i=1}^k cm_{ii}}{\sum_{i,j} cm_{ij}}\), wobei \(k\) die Anzahl der Klassen ist.
Beispiel mit dem Auto-Datensatz: Wir klassifizieren die Herkunft (origin) eines Autos in drei Klassen: “USA”, “Europe”, “Japan”, basierend auf weight und horsepower. Eine logistische Regression (mit multi_class="multinomial") wird verwendet, und die Confusion Matrix wird visualisiert.
/home/runner/work/MECH-B-4-MLDS-MLDS1/MECH-B-4-MLDS-MLDS1/.venv/lib/python3.12/site-packages/sklearn/linear_model/_logistic.py:1247: FutureWarning:
'multi_class' was deprecated in version 1.5 and will be removed in 1.7. From then on, it will always use 'multinomial'. Leave it to its default value to avoid this warning.
Genauigkeit: 0.70
Fazit: Die Multi-Class Confusion Matrix ist ein mächtiges Werkzeug, um die Leistung eines Klassifikators für mehr als zwei Klassen zu bewerten. Sie ermöglicht eine detaillierte Analyse der Fehlerarten und hilft, Schwächen des Modells zu identifizieren.
10.2.2 Fehlermetriken für Klassifikation
Bei der Bewertung eines Klassifikationsmodells liefert die Confusion Matrix detaillierte Informationen, aber einzelne Metriken wie Precision, Recall (Sensitivität), Spezifität und F1-Score fassen die Leistung prägnant zusammen. Diese Metriken sind besonders nützlich, um die Balance zwischen korrekten und falschen Vorhersagen zu verstehen, insbesondere bei unbalancierten Datensätzen.
Genauigkeit (Accuracy): Anteil der korrekten Vorhersagen (TP + TN) an allen Vorhersagen. Sie beantwortet: „Wie viele Vorhersagen waren insgesamt korrekt?“
, wobei \(TP\) True Positives, \(TN\) True Negatives, \(FP\) False Positives und \(FN\) False Negatives sind.
Precision (Präzision): Anteil der korrekten positiven Vorhersagen unter allen positiven Vorhersagen. Sie beantwortet: „Wie viele der als positiv klassifizierten Fälle sind tatsächlich positiv?“
\[\text{Precision} = \frac{TP}{TP + FP}\]
, wobei \(TP\) True Positives und \(FP\) False Positives sind.
Recall (Sensitivität, True Positive Rate): Anteil der korrekt identifizierten positiven Fälle unter allen tatsächlichen positiven Fällen. Sie beantwortet: „Wie viele der tatsächlichen positiven Fälle wurden gefunden?“
\[\text{Recall} = \frac{TP}{TP + FN}\]
, wobei \(FN\) False Negatives sind.
Spezifität (True Negative Rate): Anteil der korrekt identifizierten negativen Fälle unter allen tatsächlichen negativen Fällen. Sie beantwortet: „Wie gut erkennt das Modell die negativen Fälle?“
\[\text{Spezifität} = \frac{TN}{TN + FP}\] , wobei \(TN\) True Negatives sind.
F1-Score: Harmonisches Mittel von Precision und Recall, um eine ausgewogene Metrik zu erhalten. Er ist besonders nützlich, wenn Precision und Recall unterschiedlich stark sind. \[F_1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}\].
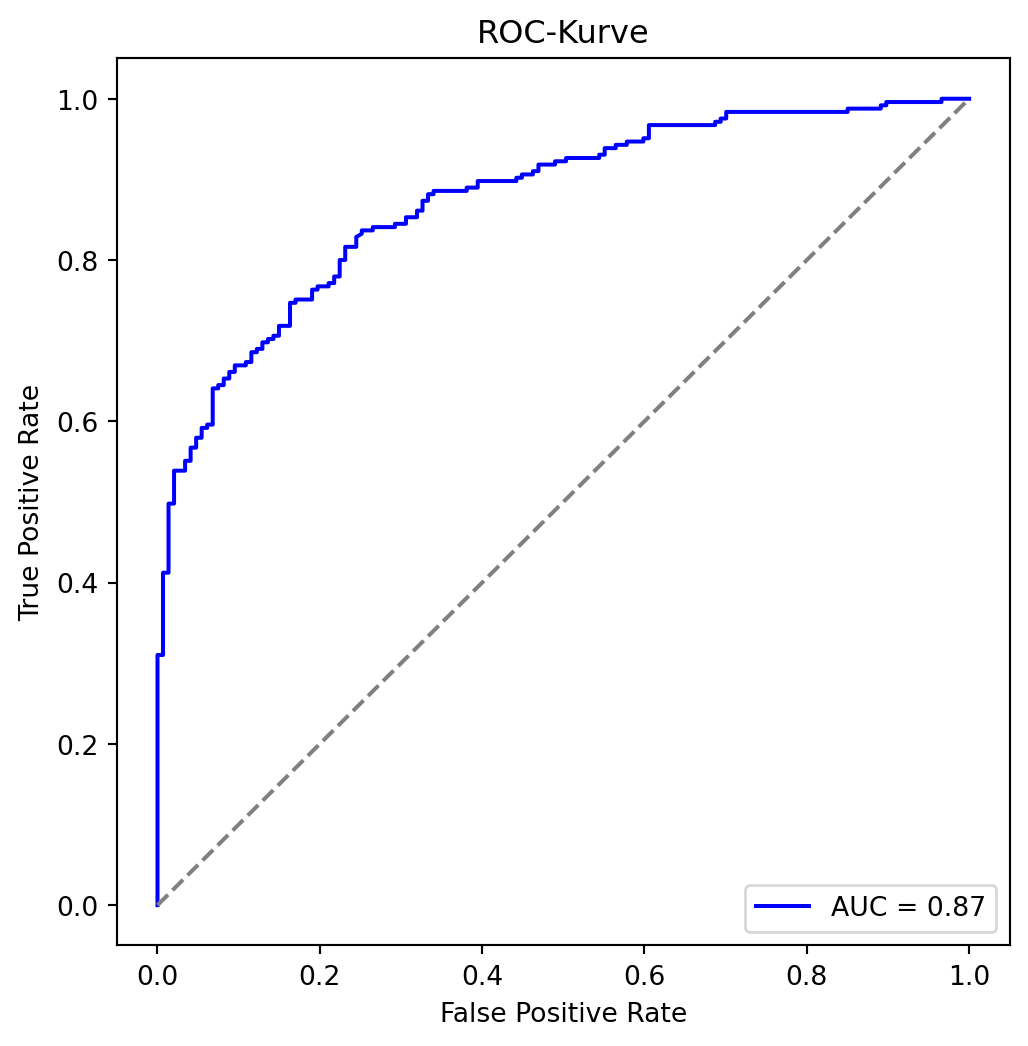
Die ROC-Kurve (Receiver Operating Characteristic) zeigt die True Positive Rate (TPR) gegen die False Positive Rate (FPR) über verschiedene Schwellenwerte. Dies lässt einen Vergleich verschidener Modelle zu, da sie die Leistung über alle möglichen Schwellenwerte hinweg darstellt.
TPR (Recall): \(\frac{TP}{TP + FN}\)
FPR: \(\frac{FP}{FP + TN}\)
Die AUC (Area Under the Curve) misst die Gesamtleistung: AUC = 1 bedeutet perfekte Klassifikation, AUC = 0.5 entspricht einem Zufallsklassifikator.
10.2.3.1 Beispiel mit dem Auto-Datensatz
Wir berechnen die ROC-Kurve und AUC für unser Modell:
Ergebnis: Ein AUC von z.B. 0.85 zeigt eine gute Unterscheidungsfähigkeit des Modells zwischen “USA” und “nicht USA”.
10.3 Fazit
Die logistische Regression ist ein effektives Werkzeug zur binären Klassifikation, wie am Beispiel des Auto-Datensatzes gezeigt. Die Confusion Matrix liefert detaillierte Einblicke in die Vorhersagefehler, während die ROC-Kurve und AUC die Modellleistung über verschiedene Schwellenwerte bewerten. Diese Methoden helfen, fundierte Entscheidungen über die Klassifikation von Autos basierend auf horsepower und weight zu treffen.